Learning to Learn to See
Learning to See by Memo Akten has always been one of my favourite pieces of artworks from the world of machine learning. It shows the inner workings of a generative model in a simple and responsive way. It was definitely the highlight for me seeing it at the AI exhibition at the Barbican a few years ago. Mick floated the idea that it would be pretty cool to get a recreation or an equivalent of Learning to See working in the browser so it could exist online.. so I couldn’t resist giving it ago!
Learning to See is based the the pix2pix model which is an image-to-image translation model which trains on pairs of images, learning to translate one input image into a desired output. It has proven itself to be very flexible and has been used in many applications:
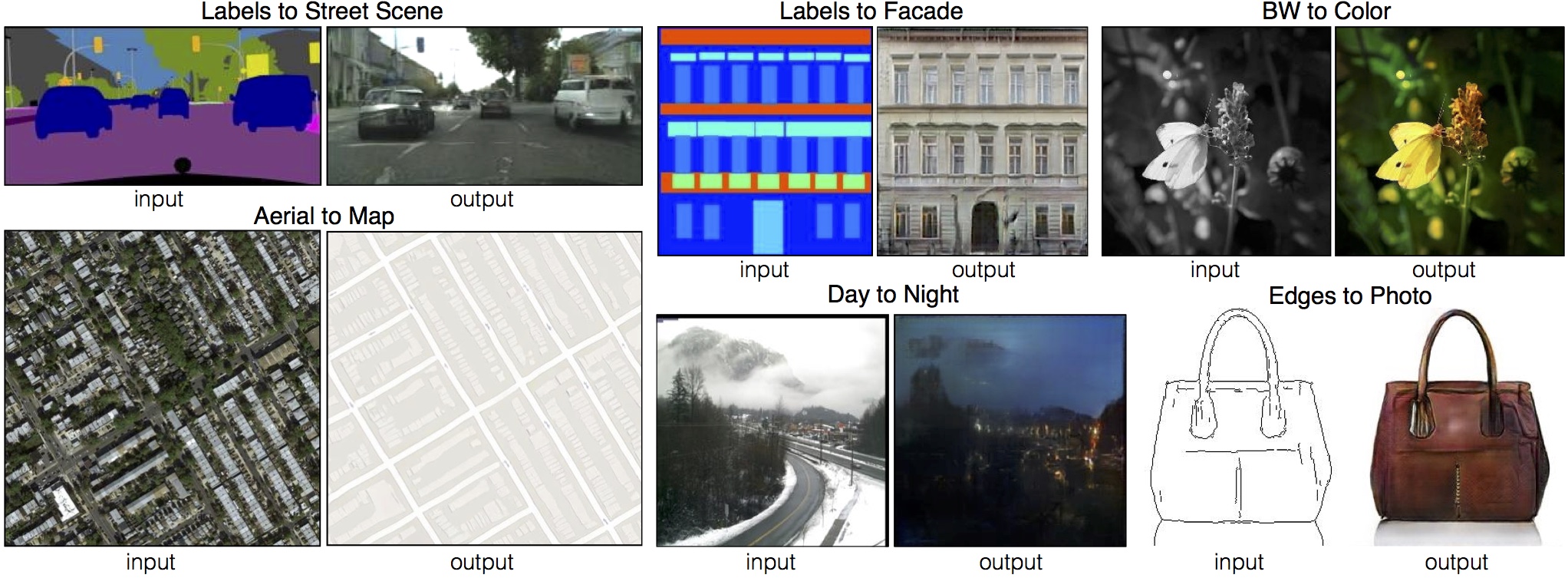
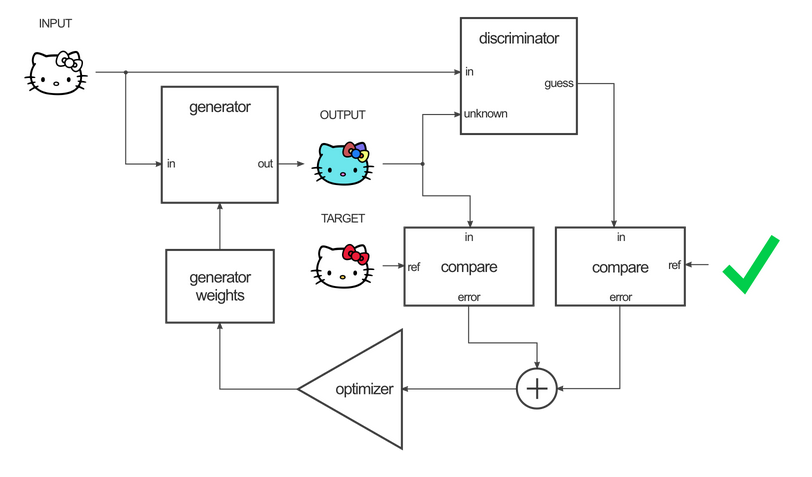
The architecture of the pix2pix model is very well described by Christopher Hesse here and he also produced this block diagram of the model (here depicting an image-colourisation application of the model):
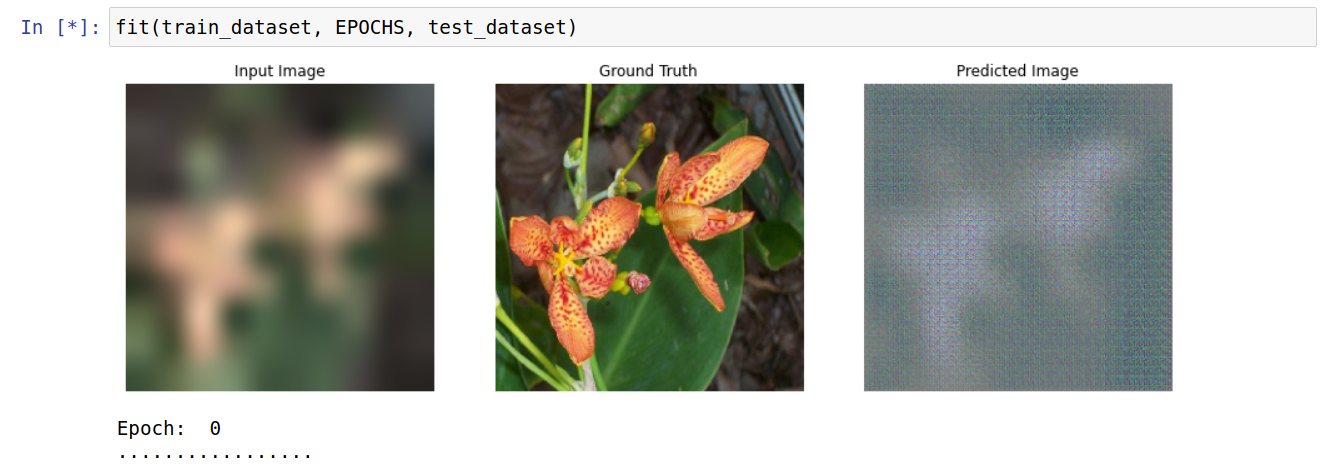
Given the broad uses of the model it is very well documented online and the official Tensorflow write-up is very good. So that’s where I started. This is the ‘hello world’ output of the model - translating coloured blocks into building facades:

The paper which accompanies the artworks reveals the details of how their particular model was trained:
The traditional pix2pix requires corresponding (input, target) image pairs. With our method, we only provide target images.
So effectively the input image is generated on the fly based on the target image from the dataset. The preprocessing pipeline is described:
- scale target image to a random size between 100% and 130% of the desired image size
- take random crop of the desired size
- depending on the nature of the dataset, randomly flip horizontally and/or vertically
- convert to grayscale
- downscale 24x with area filtering, upscale back to original size with cubic filtering
- apply random brightness of up to ±20%
- apply random contrast of up to ±15%
After working through the Tensorflow implementation of the model this seemed simple enough! I got hold of a dataset of flowers kindly made free by Oxford University (I think) and had a quick crack at creating the same preprocessing pipeline.

One thing I didn’t do was the full conversion to greyscale from colour which is described in the paper. I didn’t do this because I couldn’t quickly work out how to adjust the model to take a different shaped tensor (a single channel image rather than 3) as an input. That is a fundamental change in the architecture of the first few layers of the generator which didn’t seem like a quick change (I wanted to see it do stuff!). So instead I desaturated the image but kept the 3 channels - I think this led to worse results than the paper but I’ll come back to that.
I initially trained this on a dataset of 800 images, with a batch size of 4 for 100 epochs. And then trained the same model for a futher 150 epochs. So results of the training process are shown below:

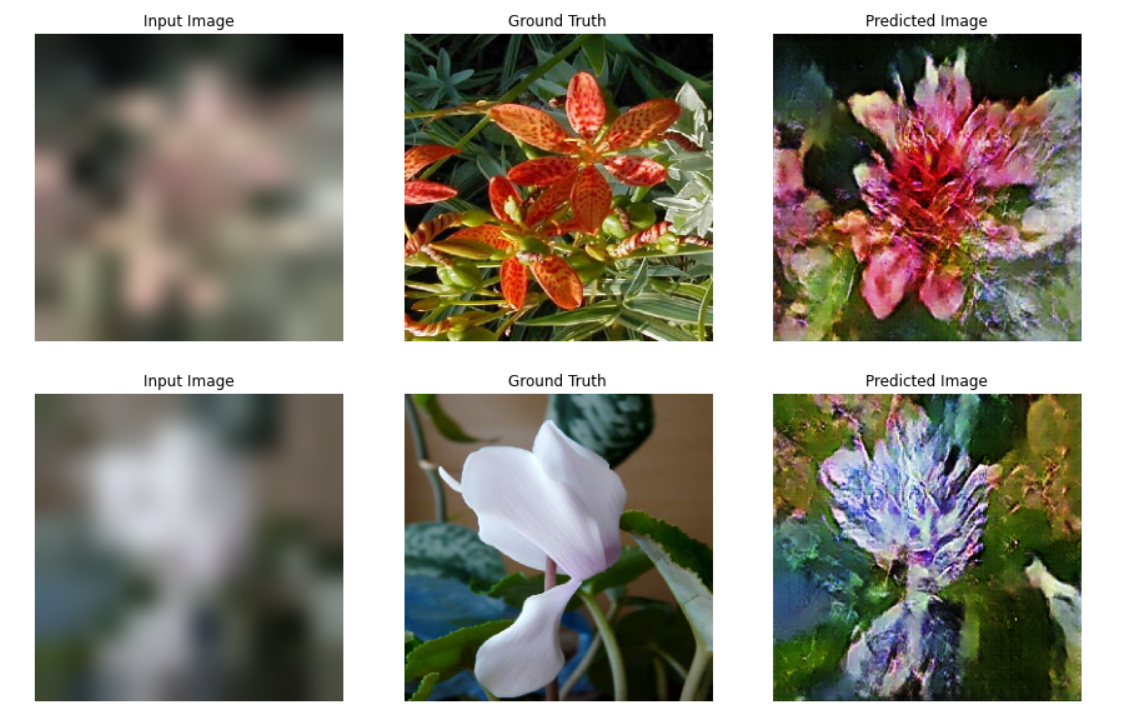

The last image is the fully trained model, and I thought the output was rather handsome. All input and output images are 256x256x3.
After this is was actually fairly simple to process video in the same way and run the frames of the video through the model. The batch of images are without preprocessing and the latter are with preprocessing:


The outcome was a little disappointing. The output from the actual Learning to See model seems to be able to react to forms a lot more deliberately to produce forms which are recognisable as waves, or nebulae, or flowers; whereas mine makes flower-y colours/shapes/textures but struggles to make a flower.

This could be down to a lot of things:
- The dataset I used is almost entirely close-up images of flowers. This means the model is never going to create an assemblage of flowers as an output.
- The preprocessing perhaps doesn’t abstract the image enough. You can see in the original paper the input images are very soft whereas mine are still a bit edgey.
- My choosing to desaturate the image rather than greyscale it might also be an issue. You can also see in the paper the input images have strong contrast; a definite range from black to white. Mine are just pretty grey. I did think at the time this could work in my favour as webcam input tends to be pretty grey and desaturated given the quality and resolution of the camera, but the input is going to be preprocessed any way so I should probably take that moment to create the stronger contrast in the input.
- My model is based on the Tensorflow implementation which uses a U-Net architecture for the generator as I believe it is easier to implement. The actual pix2pix model uses a ResNet (or Residual Neural Network) - they both serve similar purposes but who knows maybe that would change things. It doesn’t specify in the Learning to See paper which one they used.
In all it was a great exercise and got the ball rolling for me. I have since tried some other things and have more to write about but I’m going to leave this here for now…